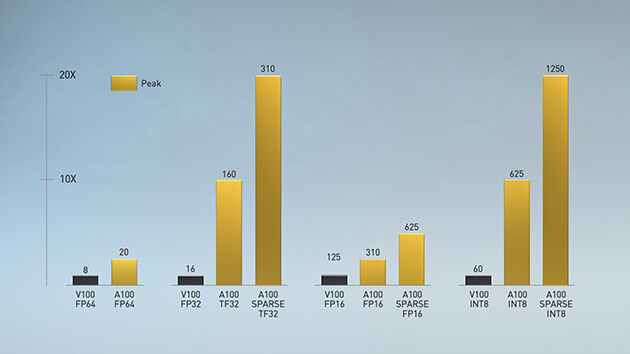
Впервые реализованная в архитектуре NVIDIA Volta™ технология тензорных ядер NVIDIA значительно ускоряет инференс и позволяет обучить алгоритмы ИИ за несколько часов, а не недель. Опираясь на эти инновации, архитектура NVIDIA Ampere предоставляет поддержку операций Tensor Float (TF32) и с плавающей точкой (FP64), ускоряя и упрощая внедрение ИИ и обеспечивая возможности тензорных ядер для HPC.
TF32 работает аналогично FP32 и до 10 раз ускоряет инференс ИИ, не требуя изменений в коде. Используя автоматическую функцию работы с различной точностью NVIDIA,исследователи могут повысить производительность в два раза, добавив всего одну строку кода. Благодаря поддержке операций bfloat16, INT8 и INT4 тензорные ядра в GPU NVIDIA A100 создают универсальный ускоритель как для обучения ИИ, так и для инференса. Обеспечивая возможности тензорных ядер для HPC, A100 позволяет выполнять матричные операции с точностью FP64 в соответствии со стандартом IEEE
Каждое приложение для ИИ и HPC работает быстрее с графическим ускорением, но не всем приложениям нужна полная мощность графического процессора A100. С MIG каждый GPU A100 можно разделить на семь полностью изолированных и защищенных на аппаратном уровне инстансов, оснащенных памятью с высокой пропускной способностью, кэшем и вычислительными ядрами. Это позволяет использовать ускорение для приложений с разной ресурсоемкостью, а также получить гарантированное качество обслуживания. Администраторы могут предложить оптимальные ресурсы GPU для любой задачи, повысить утилизацию и предоставить доступ большему числу пользователей как на физических серверах, так и в виртуализированной среде.

Масштабирование приложений на нескольких GPU требует высокой скорости передачи данных. Третье поколение NVLink в A100 удваивает скорость обмена данными между GPU до 600 Гбит/с, что почти в 10 раз превосходит показатели PCIe Gen 4. А благодаря комбинации с
NVIDIA DGX™ A100 и серверы других ведущих производителей используют технологию NVLink и NVSwitch через платы NVIDIA HGX™ A100, обеспечивающие высокую масштабируемость для нагрузок ИИ и HPC.
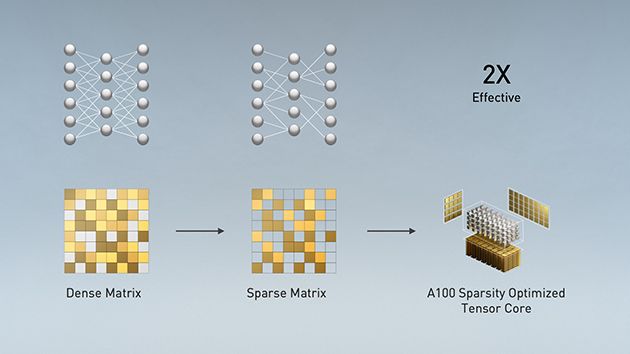
Современные сети ИИ становятся все больше и состоят из миллионов, а иногда и миллиардов, параметров. Не все эти параметры необходимы для точного прогнозирования и инференса, и некоторые из них можно преобразовать в нули, чтобы создать «разреженные» модели без ущерба для точности вычислений. Tensor Cores in A100 обеспечивают производительность до 2X раз выше для разреженных моделей. Хотя функция разреженности в основном предназначена для инференса ИИ, с ее помощью можно также повысить скорость тренировки модели.

A100 обеспечивает значительный объем памяти для вычислений в дата-центре. Для максимальной утилизации вычислительных движков платформа оснащена пропускной способностью памяти 1,5 Тб/с, что на 67% быстрее технологии предыдущего поколения. Кроме того, для максимальной вычислительной мощности A100 имеет значительно больший объем памяти, включая кэш второго уровня 40 Мб, что в 7 раз больше, чем у систем предыдущего поколения.

Сочетание архитектуры NVIDIA Ampere и сетевой карты Mellanox ConnectX-6 Dx SmartNIC в NVIDIA EGX™ A100 обеспечивает непревзойденную мощность вычислений и ускорение сетей для обработки больших объемов данных на периферийных устройствах. Mellanox SmartNIC обеспечивает аппаратную разгрузку безопасности и дешифровку данных со скоростью до 200 Гбит/с, а GPUDirect™ передает кадры непосредственно в память графического процессора для обработки с помощью ИИ. С помощью EGX A100 компании могут быстрее, эффективнее и безопаснее развертывать ИИ на периферийных устройствах.